23 / 01 / 03
FPGA基础-Verilog HDL相关
-
功耗优化相关
-
额外的routing增加布线拥塞以及功耗,解决方法:
-
调整设置/设定/约束
-
增加pipeline流水线寄存器,减短长路径
-
-
存储资源功耗:
-
强制使用小块MLAB,避免使用大块M20K,适用于大位宽但深度浅的memory
-
功耗主要来自于动态时钟,充放电RAM core导致功耗增加,可减少memory器件clocking events来减少功耗
-
使用clock enable信号使得memory器件在不使用的时候达到几乎为0的功耗消耗(无RAM core充放电)
-
使用更窄/更深的memory实现,用max_block_depth控制RAM深度,此时编译器会加入额外的decoder和mux逻辑,
-
-
Pipeline流水线
-
提升速度,缩短逻辑深度,减少逻辑切换,不改变原有逻辑功能
-
会增加资源/寄存器使用量,影响延迟和吞吐率,若设计存在glitch可能会增加功耗
-
-
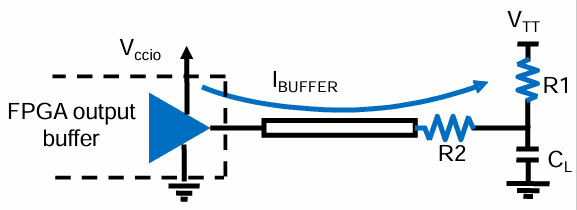
I/O功耗
-
功耗公式:

-
更低的I/O电压消耗功率更低
-
阻性上拉标准(SSTL/HSTL):输出波动小,高频应用中动态功耗较低,但由于持续驱动静态电阻,静态功耗高
-
不上拉的标准(LVTTL/LVCMOS):V = Vccio,高频率时高动态功耗,但由于无静态电阻驱动,低静态功耗
-
-
-
一些基本语法
-
赋值:
assign out = in; -
翻转赋值:
assign out = ~in; -
异或:
assign out = a ^ b; -
同或:
assign out = ~(a ^ b); -
casez:可在case中引入don't-care位:
always @(*) begin casez (in[3:0]) 4'bzzz1: out = 0; // in[3:1] can be anything 4'bzz1z: out = 1; 4'bz1zz: out = 2; 4'b1zzz: out = 3; default: out = 0; endcase end -
-
Intel Quartus设计流程:
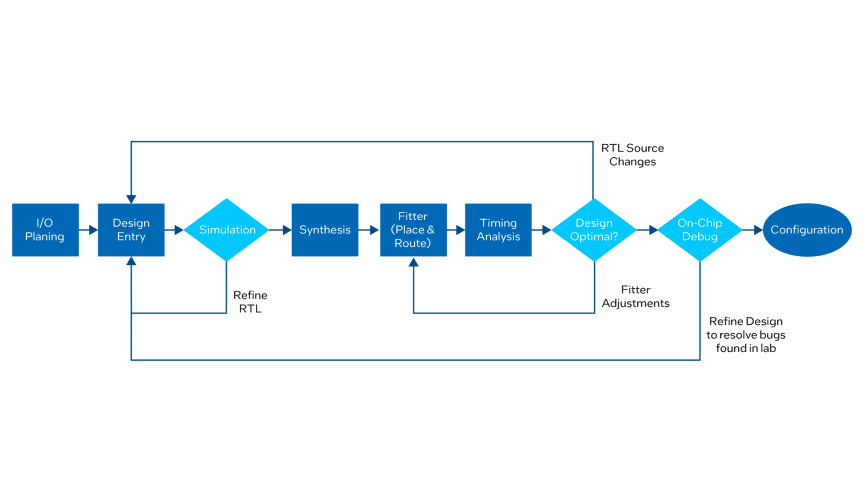 Intel官方FPGA设计流程相关文档 ,相当详细且带在线学习课程。
Intel官方FPGA设计流程相关文档 ,相当详细且带在线学习课程。
Powered by Gridea